La revolució tecnològica en la qual estem immersos durant els últims anys està generant una corba de creixement clarament exponencial entorn de la creació no continguda (i incontenible) de la unitat atòmica d’informació relacionat amb els seus processos, el que tothom ja citem amb matisos gairebé totèmics como la dada.
No en va, el volum total d’informació generat per tots els sistemes que utilitzem en l’actualitat va ascendir, al llarg de l’exercici 2019, a la no menyspreable xifra de 45 Zettabytes (ZB, per als que no estiguin familiaritzats amb aquesta unitat de mesura, equival a 1.000 milions de Terabytes). I aquesta esfera global de dades (global datasphere), ha mantingut un creixement exponencial l’acceleració de la qual apunta al fet que, en diverses prediccions, com les fetes per IDC, es converteixi en 175 Zettabytes per al 2025, fruit de l’arribada i implantació de tecnologies com el 5G i la conseqüent revolució de la internet de les coses (IoT).
Molts parlen per això de l’adveniment del que han denominat la Nova era de la dada entre 2024 i 2025.
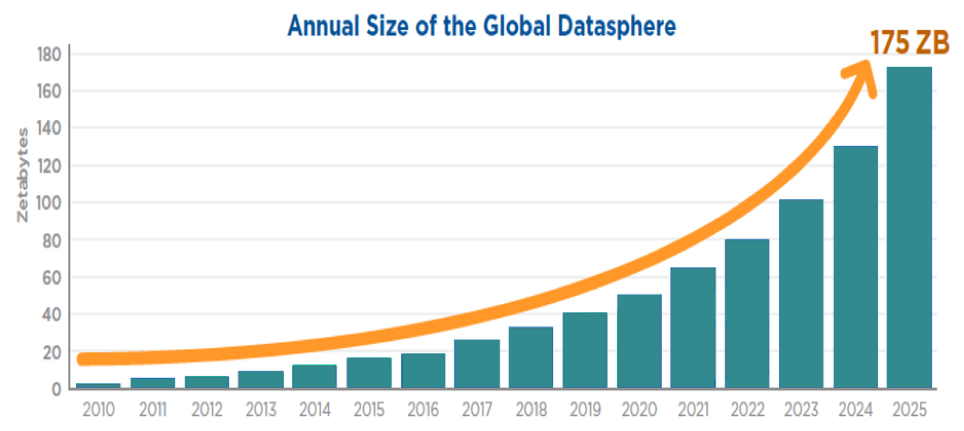
I la realitat no ha fet més que superar habitualment aquestes prediccions. Aquest tipus de volumetries generarà, i ja genera, seriosos problemes per al seu emmagatzematge i salvaguarda, ja que les arquitectures que el suporten han d’alinear-se a les esmentades taxes de creixement (on premise, cloud, edge…). De fet, és habitual que els mitjans es facin eco de problemes d’emmagatzematge dels principals distribuïdors cloud, i dels nous sostres generats després de la seva resolució.
Però més enllà de les qüestions i estratègies del seu emmagatzematge, que són clarament un desafiament tecnològic, el realment important és que no oblidem que la dada és un combustible que, sense un tractament, refinament i processament adequat, és només això, un combustible amb un altíssim potencial, una capacitat sense aprofitar. I amb les volumetries comentades, aquest refinament, aquest processament en el qual convertim la dada en informació de valor per a les organitzacions que les generem, és un repte a què ja ens enfrontem avui dia.
Més enllà dels titulars, ja ens trobem immersos en aquesta era de les dades, i l’estratègia que adoptem marcarà quant ens aprofitem d’aquesta informació.
En un enfocament “clàssic”, les organitzacions disposem de diversos sistemes en els quals introduïm informació en repositoris de dades, a través de plataformes que faciliten l’esmentat processament. L’usuari introdueix i modifica informació del sistema, basat en sistemes de filtratge, habitualment toscos, i l’objectiu exclusiu dels quals, per a allò que van ser creats, és pròpiament l’entrada de dades.
Com un primer pas al camí de l’obtenció d’informació, es comença donant servei a través d’informes, amb certa capacitat de selecció prèvia a la seva generació, en què el destinatari rep informació ja processada i que la consumeix tal com és servida.
Tanmateix, aquestes audiències (conegudes en determinats contextos com “passives”, ja que no interactuen amb la dada, únicament la consumeixen), cada vegada necessiten que aquesta informació tingui un comportament més dinàmic. Pot ser que un informe periòdic sigui la solució en determinades circumstàncies, però cada vegada volem rebre’ls com a resultat del fet que hi concorrin una sèrie condicions, i en diferents formats, dispositius, ocasions… Així doncs, cada vegada més, desitgem que els continguts que rebem s’adaptin a les nostres necessitats i interessos. En el nostre context, un responsable de servei requereix tenir informació processada i detallada en el moment que hi hagi una situació d’alerta que necessiti de la seva actuació, per exemple, però també un ciutadà espera obtenir informació associada als seus tràmits, obligacions i fins i tot interessos en iniciatives com els portals al ciutadà. Aquests usuaris connecten amb la informació gràcies a sistemes adaptatius que ajusten les dades, la manera de mostrar-les, fins i tot el moment en què són generades, d’acord amb les necessitats de cada context.
I tenim també consumidors d’informació amb una capacitat més activa. Necessiten seleccionar de manera interactiva, processar, analitzar la informació introduïda en els diferents sistemes origen, de manera que puguin obtenir conclusions, punts de millora o correcció, patrons de comportament…
Tot això, a més, de manera autònoma, i amb eines que ajudin que un coneixement profund de les arquitectures que han suportat la creació d’aquestes dades no sigui necessari. Per a això cal disposar de capes semàntiques, que aquests usuaris analítics puguin utilitzar per als seus estudis, sense necessitat de coneixement de BD o models complexos. I tota aquesta informació dins de contextos governats, que garanteixin la seguretat, així com la qualitat de les conclusions processades.
Encara més enllà, l’usuari genera el seu propi contingut analític que pot compartir amb la resta de l’organització. I el mateix sistema l’ha d’ajudar en aquesta generació, fent propostes automàticament, de manera que, d’acord amb el focus d’estudi de l’esmentat usuari, proposi aquelles anàlisis que habitualment s’ajusten més a aquest (a través d’estratègies d’aprenentatge automàtic) i contestant a les qüestions de l’usuari, ja no només amb cerques tradicionals, sinó també amb cerques difuses i fins i tot processament de llenguatge natural (Natural Language Processing), de manera que se li permeti qüestionar sense cap “patró tecnològic” obtenint anàlisis associades a la qüestió processada.
En aquest entorn, a més, les “línies vermelles” tradicionals han de desdibuixar-se.
La visió de sistemes d’introducció i gestió de dades estanques que són “intervingudes” per altres d’analítiques processades per audiències diferents serà cosa del passat. Sense que siguem fins i tot conscients, les nostres plataformes tradicionals hauran d’incloure capacitats analítiques en els seus processos d’introducció d’informació, amb grans capacitats de selecció, elements visuals intuïtius, noves dimensions d’anàlisi com la geogràfica…
D’aquesta manera, previ a la introducció d’informació, l’usuari (basat en un sistema que aprèn amb ell) analitza la situació a què s’enfronta (obté informació del ciutadà a qui dona servei, un patró del seu comportament, un perfil d’acord amb la seva situació censal…) selecciona l’acció, procediment a aplicar, basat en les esmentades ajudes, tornant a generar nova informació, noves dades. I aquestes dades entren de nou en el cicle de generació i anàlisi, nodrint els processos següents. Cada vegada més amb la necessitat, de mnera integrada, pràcticament en temps real. Aquestes integracions, i aquests nous cicles de treball, aquesta nova intel·ligència activa, passaran a formar part del nostre dia a dia, facilitant la nostra eficiència, qualitat del nostre treball i la millora dels nostres serveis prestats.
Per sobre de xifres estratosfèriques i prediccions superades per la realitat, el ritme en el qual la informació que processem creix ens obliga que disposem de sistemes que s’adaptin de manera dinàmica a les necessitats de les nostres organitzacions, de manera que puguem impulsar-nos a través de les dades (ser més data-driven), que aprofitem al màxim el combustible d’aquesta ingent quantitat de dades que ja avui estem processant.
És per això que, el que alguns profetitzen com a Nova era de la dada, ja no és una predicció, no és un “futurible”, i podem afirmar que l’Era de la dada és ara.




